

Building an Apartment Rent Pricing App I: Data Collation via Web Scraping


Gathering Data for an E2E ML Application Development Process.
Okay. Let's just get down to it!
If you're wondering why we're just getting down to it, maybe you should read the overview article first. This is the first article in the series (Building an apartment rent pricing app end-to-end) where we build out our dataset.
The usual first step in most Data Science projects is securing an appropriate and relevant dataset - and that is what we'd be doing here - by building our relevant dataset via web scraping. If this is your first time with web scraping, I'd advise that you skim through this web scraping tutorial I wrote a while ago, to build up your familiarity.
TL;DR
Here's the link to the code on GitHub:
Getting Started
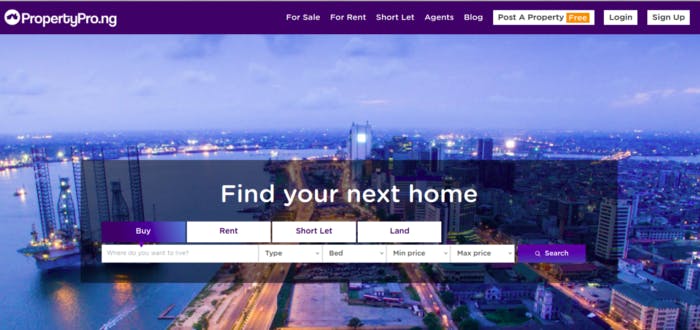
We'll be scraping apartment listings from propertypro.ng and saving the loot in CSV files for further usage. Here's how the website looks like:
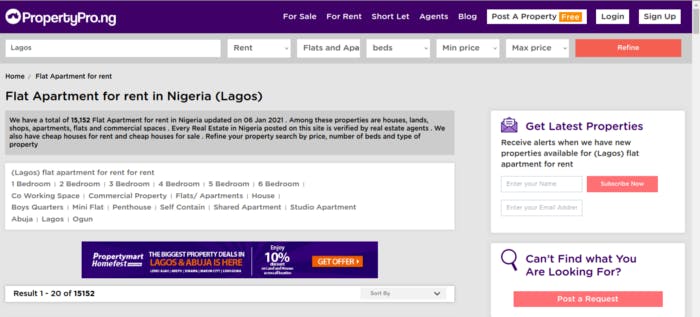
We'll click on Rent, type Lagos in the search bar below Rent, click on the Type dropdown, select Flats and Apartments, and click on the Search button. The new page should look like this:
Scrolling down, we should see something that resembles this:
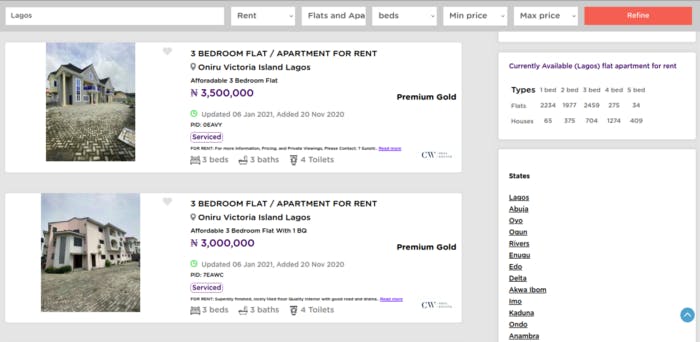
Now let's check out the layout of the site. You'd notice that in each apartment listing, there's a title, an address, the house perk written and encased in purple, a description with a Read more link at the end of the description, and the bedrooms, baths, and toilets details at the bottom part.
Those are the information we'd be retrieving for each apartment listing on the site.
We'll use the Python Requests library to retrieve the webpages' data, and BeautifulSoup to parse the HTML. Let's start by importing the necessary libraries.
import requests
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
Numpy and Pandas are imported by habit, LOL. But they should play a role at some point.
Now let's copy the URL of our current page on the website and pass it into the get function of the requests library. Then we'd pass the contents into BeautifulSoup:
r = requests.get('https://www.propertypro.ng/property-for-rent/flat-apartment/?search=Lagos&bedroom=&min_price=&max_price=')
soup = BeautifulSoup(r.content, 'html5lib')
We could print out soup and check it out. We'd get this;
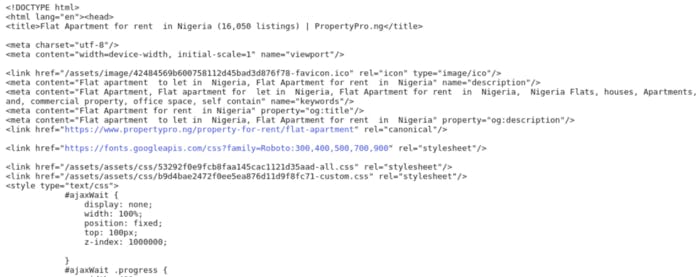
That's the HTML code that made up the webpage, and upon inspection, it looks like it contains everything we need. Now let's examine the page elements and figure how a way to parse the page data.
Go back to the apartment rents listings page (the one we opened earlier) on the site and right-click anywhere on the page. Click on Inspect and the page should look like this:
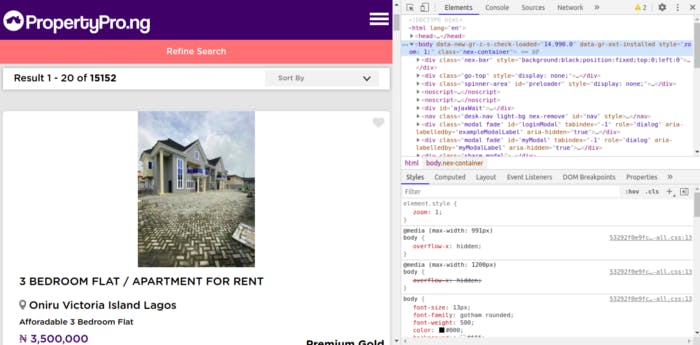
Checking out the Inspect tool by RHS, there's an arrow pointing up at the upper left part of the Inspect tool's part of the screen. Click on it, and then click on the data on the page. Note the spot highlighted in blue - It should look like this:
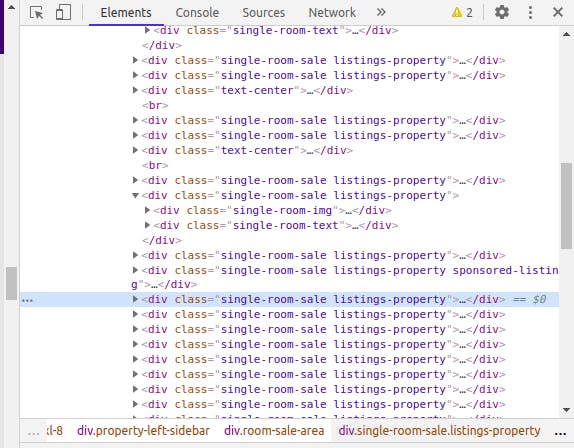
Clicking on the dropdown icon beside it and exploring further, we'd notice that the address is encased in a h4 tag, the price in a h3 tag enclosed within a div tag, the description in a div tag, and so on.
Pulling out all the Individual Specs
Let's now begin building out our code to extract all the individual specs of each apartment listing:
listing_divs = soup.select('div[class=single-room-sale\ listings-property]')
In the above code, I'm using the select function of BeautifulSoup to all the divs that have a class with the name single-room-sale listings-property and saving them to a list called listing_divs. Let's check the number of elements in listing_divs with the len function:
print("Number of apartment listings on a page:", len(listing_divs))
Here's the output:

This signifies that there could be only 20 apartment listings on a web page. It also means that each of the 20 elements in listing_divs represents an apartment listing and all its details. Now we could pick them one by one, extract all the features we want, and move on to the next page. Let's start with the first element in listing_divs.
listing_divs[0]
This gives us the below output:
If you look hard enough, you should be able to see all the features that we want to extract from each apartment listing. We'll start extracting them one by one now:
listing_divs[0].select('h4')[0].text
Here we are trying to retrieve the address, which is enclosed in a h4 tag. The result is in a list so we had to extract it by calling the first index of the list. Then we call the text function to retrieve the string from the tag. This gives us the following output:

That's pretty straightforward! Next, let's try to extract the price tag:
listing_divs[0].select('h3[class*=listings-price]')[0].text.strip()
The price is encased in a h3 tag with class which part of its name is listings-price. The strip function attached to the end is to remove the leading and trailing whitespace around the gotten value. Here is the result:
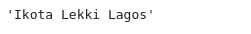
Next is the number of bedrooms, bathrooms, & toilets:
listing_divs[0].select('div[class*=fur-areea]')[0].text.strip().split('\n')
All the 3 features are located in the div tag with class part of its name is fur-areea. They are in separate span tags but once we called the text function on the div, every string in the div tag would be extracted as a single string. We applied the strip function to remove leading and trailing whitespace, then we split the gotten string by the new-line escape characters in the string. Here is the result:

The last feature to extract is the description data.
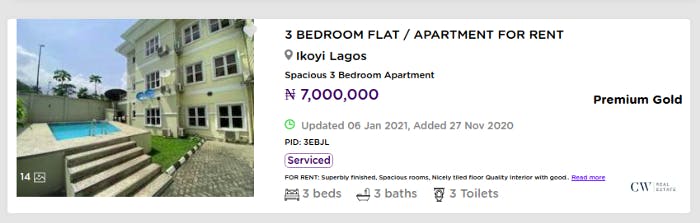
See the Serviced theme written and encircled in purple? See the line directly under it? Those are what we'd extract next, as they seem to provide relevant information about the apartment that we might not get just by staring at the price and number of rooms. We'll start the retrieval of the theme:
listing_divs[7].select('div[class*=furnished-btn]')[0].text.replace('\n', ' ').strip()
The theme is located in a div tag with a class whose part of its name is furnished-btn. Then we replaced every new-line escape character with a single space and finally stripped off the leading and trailing whitespace. Here is the result:

Here we have Serviced and Newly Built.
Cleaning up the line directly under it, we'd have:
listing_divs[7].select('div[class*=result-list-details]')[0].p.text.replace('Read more', '').replace('FOR RENT:', '').strip()
Here we are extracting from a div tag with a class whose part of its name is result-list-details. Then we got the p tag within the div tag and extract its string. Finally, we replaced Read more and FOR RENT: with empty strings and strip off the extra whitespace. And we got this:
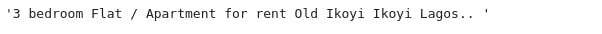
Now that we've extracted out all the necessary information, let's put everything together and test it further.
Testing Everything Altogether
Check out the code below:
all_listings_data = []
for indv_listing in listing_divs:
address = indv_listing.select('h4')[0].text
price = indv_listing.select('h3[class*=listings-price]')[0].text.strip()
listing_data = [address, price]
utilities = indv_listing.select('div[class*=fur-areea]')[0].text.strip().split('\n')
listing_data.extend(utilities)
description = indv_listing.select('div[class*=result-list-details]')[0].p.text.replace('Read more', '').replace('FOR RENT:', '').strip()
extra = indv_listing.select('div[class*=furnished-btn]')[0].text.replace('\n', ' ').strip()
listing_data.append(extra + description)
all_listings_data.append(listing_data)
pd.DataFrame(all_listings_data)
Now let's walk through everything one by one:
- I initialized an empty list called
all_listings_data, and loop throughlisting_divs(remember that listing_divs contains 20 apartment listings). - For each loop, I extracted the address and price and put them in a list called
listing_data. I extracted the number of rooms (beds, baths, and toilets) and append them tolisting_data. I also extracted the description and the theme in the variabledescriptionandextrarespectively, concatenate the 2 strings together, and append them tolisting_data. Then I appendlisting_datatoall_listings_data. - Finally, I converted all_listings_data to a Pandas DataFrame.
Now let's check out the result:
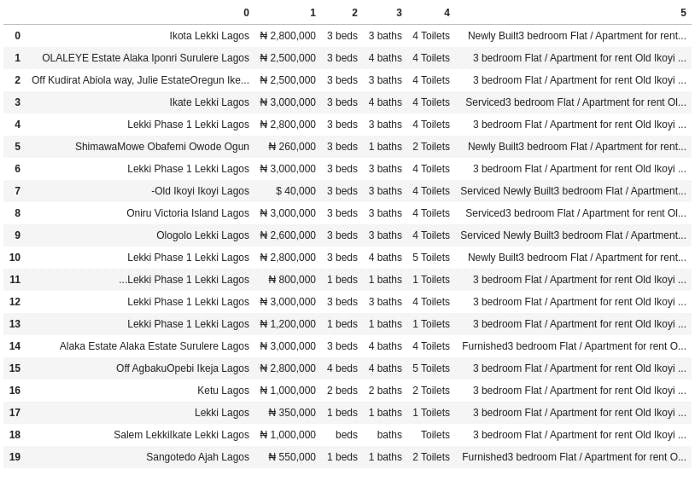
Great! Our work is almost done. All that is left to do is to write a dynamic function that'd get the apartment listings - provided the city's name - and convert it to a Pandas DataFrame and save it locally as a CSV file.
Dynamic Function to Retrieve Apartment Listings Data
def parse_listing_data(location, max_price, rows_of_data=2000):
all_listings_data = []
page_num = 0
while page_num < (rows_of_data / 20):
url = "https://www.propertypro.ng/property-for-rent/flat-apartment/?search=" + location \
+ "&bedroom=&min_price=&max_price=" + str(max_price) + "&page=" + str(page_num)
r = requests.get(url)
soup = BeautifulSoup(r.content, 'html5lib')
listing_divs = soup.select('div[class=single-room-sale\ listings-property]')
if len(listing_divs) == 0:
break
for indv_listing in listing_divs:
address = indv_listing.select('h4')[0].text
price = indv_listing.select('h3[class*=listings-price]')[0].text.strip()
listing_data = [address, price]
utilities = indv_listing.select('div[class*=fur-areea]')[0].text.strip().split('\n')
listing_data.extend(utilities)
description = indv_listing.select('div[class*=result-list-details]')[0].p.text.strip().replace('Read more', '').replace('FOR RENT: ', '')
extra = indv_listing.select('div[class*=furnished-btn]')[0].text.strip().replace('\n', ' ')
listing_data.append(extra + description)
all_listings_data.append(listing_data)
page_num += 1
listing_df = pd.DataFrame(all_listings_data, columns=['neighborhood', 'price', 'beds', 'baths', 'toilets', 'extra'])
listing_df.to_csv("rent_listings_"+location+".csv", index=False)
return listing_df
There is a lot going on here, so let's go through the code line by line:
- So we create a function called
parse_listing_dataand we set up 3 arguments with one of them optional. The first is the location we want to retrieve data for, the second is the price ceiling - it won't do much good to scrape data of overpriced apartments, while the last parameter is the number of apartment listings data we'd like to retrieve. - Then we have an empty
list all_listings_dataandpage_numset to 0. - We have a while loop with the condition to iterate if
page_numis not greater than the number of pages we want to retrieve data from. Suppose we specify that we want only 200 rows of data, since a page contains 20 apartment listings, the loop condition will make sure that we loop through only 10 pages of data. - Then we have the URL broken down so we could fit in
location,max_price, andpage_numinto the URL using string concatenation. - The next line gets the HTML data of the URL using the requests'
getfunction and we pass its contents into BeautifulSoup for HTML parsing. - Afterward, we select all the apartment listings on the page. We also specify that if the length of
listing_divsis equal to zero - which means that there are no apartment listings on that page - the loop should be terminated. - Then we loop through each individual listing and retrieve its address, price, number of (bedrooms, bathrooms, toilet), and description. Next is to append them to
all_listing_data. page_numis increased by 1 and the loop with iterate again,page_numis no longer less than the number of pages we want to scrape data from.- Next thing is to convert
all_listing_datainto a Pandas DataFrame while also specifying the column names, then save the output into a CSV file whose name would be suffixed by the location name provided. - Then we return the DataFrame and that's it!
Using the Function to get Data for Different Cities
Finally, let's test out the function by passing it the necessary arguments. We'll start with Lagos:
lagos_data = parse_listing_data('lagos', 2500000, 5000)
lagos_data
Here, we pass in lagos as our preferred location, 2.5 million naira as our maximum price, and 5000 as the number of rows we want. Here's our result:
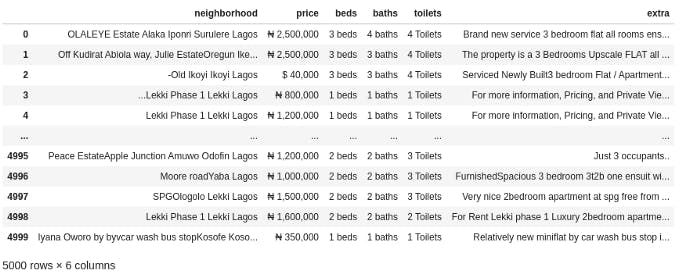
And that's it! The CSV file containing this data was saved on our local storage automatically (as we specified in the function code). Also, note that some of the apartments are priced in dollars! This would be taken care of during preprocessing.
Let's try out the same for Ibadan:
ibadan_data = parse_listing_data('oyo', 3000000, 2000)
ibadan_data
We specified oyo, 3 million naira as our maximum apartment price, and 2000 as the rows of data we want.
Alas! Only 512 rows of apartment data are available in Ibadan.
We do the same for Abuja, Ogun, and Port Harcourt.
abuja_data = parse_listing_data('abuja', 4000000, 3000)
ogun_data = parse_listing_data('ogun', 2000000, 2000)
ph_data = parse_listing_data('rivers', 3000000, 2500)
Once you are done, you'd notice that Abuja yielded about 700 rows of data. Ogun yielded about 190 rows, while Port Harcourt yielded just 100 rows of data. And we are done here! Cheers if you made it this far!

Summary
In this tutorial, we systematically went through the whole process of building our apartment listings datasets by scraping off data from the number 1 real estate pricings website in Nigeria. Here is the code on GitHub.
Next in line is Data Wrangling, which includes cleaning the data into a format that we can work with and extracting new features from the existing features. This should consume more than 40% of our total development time.
So long, folks! If you have any questions, feel free to reach out to me either through the comments here, on Twitter, or via LinkedIn.