


A hands-on guide to mastering the first baby steps in building Machine Learning applications.
Machine Learning is continuously evolving. Along with that evolution comes a spike in demand and importance. Corporations and startups are needing Data Scientists and Machine Learning Engineers now more than ever to turn those troves of data into useful wisdom. There’s probably not a better time than now (except 5 years ago) to delve into Machine Learning. And of course, there’s not a better tool to develop those applications than Python. Python has a vibrant and active community. Many of its developers came from the scientific community, thus providing Python with vast numbers of libraries for scientific computing.
In this article, we will discuss some of the features of Python’s key scientific libraries and also employ them in a proper Data Analysis and Machine Learning workflow.
What you will learn;
- Understand what Pandas is and why it is very integral to your workflow.
- How to use Pandas to inspect your dataset
- How to prepare the data and feature-engineer with Pandas
- Understand why Data Visualization matters.
- How to visualize data with Matplotlib and Seaborn.
- How to build a statistical model with Statsmodel.
- How to build an ML model with Scikit-Learn's algorithms.
- How to rank your model’s feature importances and perform feature selection.
If you’d like to go straight to code, it is here on GitHub.
Disclaimer: This article assumes that
- You have at least, a usable knowledge of Python and
- You already are familiar with the Data Science/Machine Learning workflow.
Pandas
Pandas is an extraordinary tool for data analysis built with the goal of becoming the most powerful and flexible open-source data analysis/manipulation tool available in any language. Let’s take a look at what Pandas is capable of:
Data Acquisition
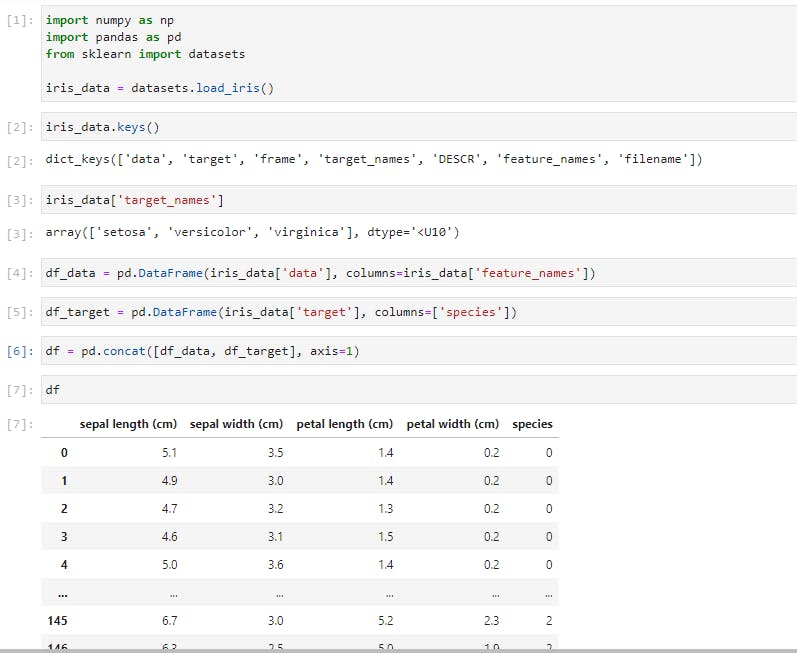
In the above cells, you’d notice that I have imported the classic dataset, the Iris dataset, using Scikit-learn (we’ll explore Scikit-learn later on). I then passed the data into a Pandas DataFrame while also including the column headers. I also created another DataFrame to contain the iris species which were code-named 0 for setosa, 1 for versicolor, and 2 for virginica. The final step was to concatenate the two DataFrames into a single DataFrame.
When working with data that can fit on a single machine, Pandas is the ultimate tool. It’s more like Excel, but on steroids. Just like Excel, the basic units of operations are rows and columns where columns of data are Series, and a collection of Series is the DataFrame.
Exploratory Data Analysis
Let’s perform a few common operations;
Data Slicing
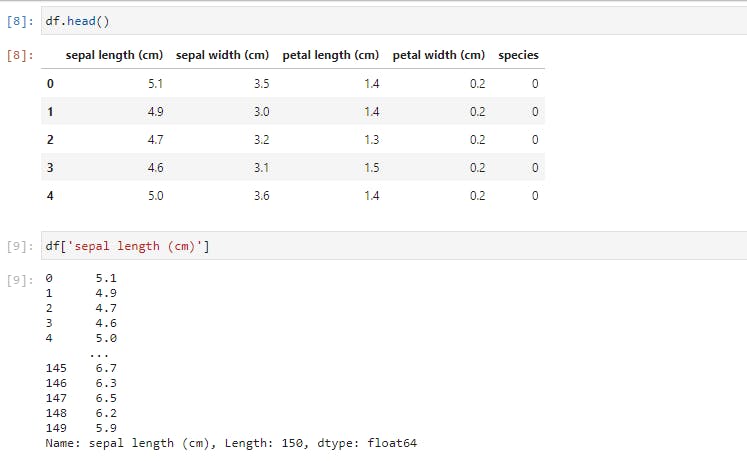
The .head() command will return the first 5 rows. The second command was to select a single column from the DataFrame by referencing it with the column name.
A different way of performing data slicing is by using the loc and iloc methods.
To use iloc, we have to specify the rows and columns we want to slice by their integer index, while for loc, we have to specify the names of the columns that we want to filter out.
loc gets row (or columns) with a particular label from the index while iloc gets rows (or columns) location at particular positions in the index (so it only takes integers)
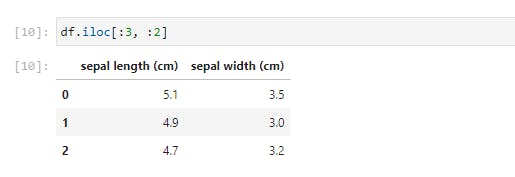
Using .iloc, we just selected the first 3 rows and 2 columns of the DataFrame. Let’s try something more difficult;
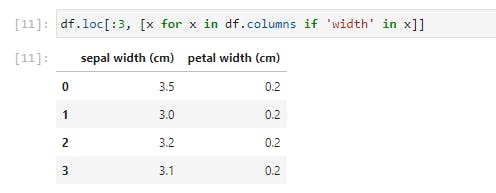
Here we iterate through df.columns, which would return a list of columns, and select only the columns with ‘width’ in their names. This seemingly small function is quite a powerful tool when employed on far larger datasets.
Next, let’s use another way of selecting a portion of the data by specifying a condition to be satisfied. We’ll look at the unique list of species, then select one of those.
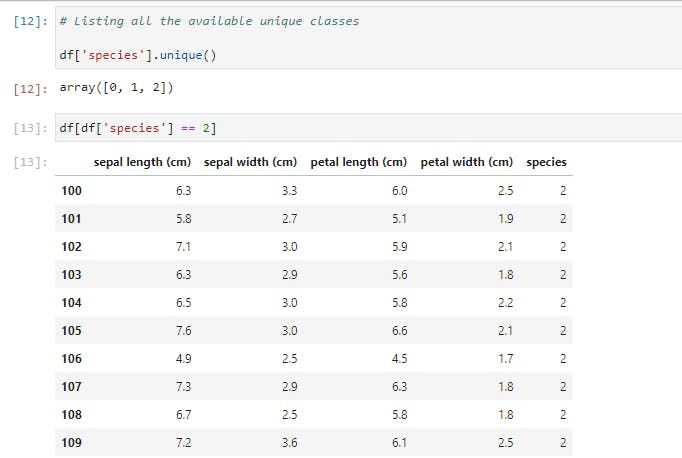
Notice that our DataFrame only contains rows of Iris-virginica species (represented by 2). In fact, the size is 50, as opposed to the original 150 rows.
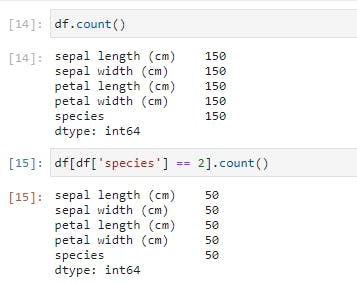
You’d also notice that the index on the left retains the original row numbers, which might cause issues later. So we could save it as a new DataFrame and reset the index.
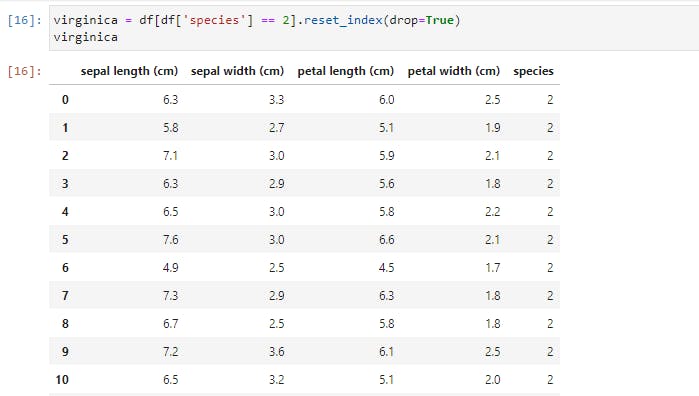
We selected this new DataFrame by specifying a condition. Now let’s add more conditions. We’ll specify two conditions on our original DataFrame.
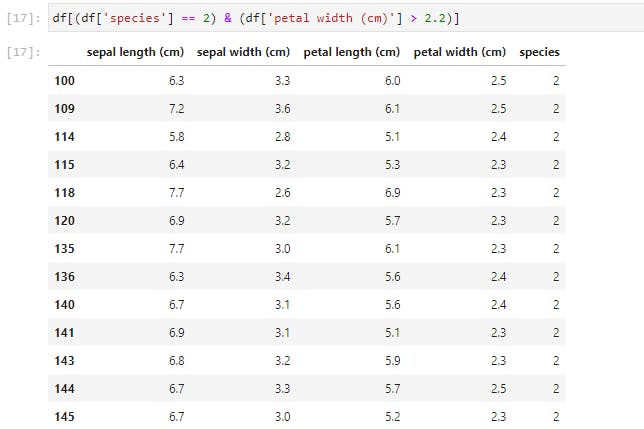
You may reset the index of this new DataFrame by yourself, as an exercise.
Descriptive Statistics
Now let’s try and get some descriptive statistics from our dataset;
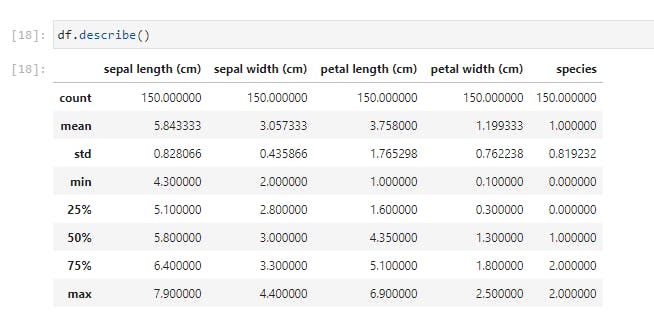
Using .describe() method, I just received a breakdown of the descriptive statistics for each of the columns. I could spot the counts of all the columns and easily note if there are missing values. I could see the mean, standard deviation, median, mode, and I could also note if the data is skewed. I could also pass in my own percentiles if I want more granular information;
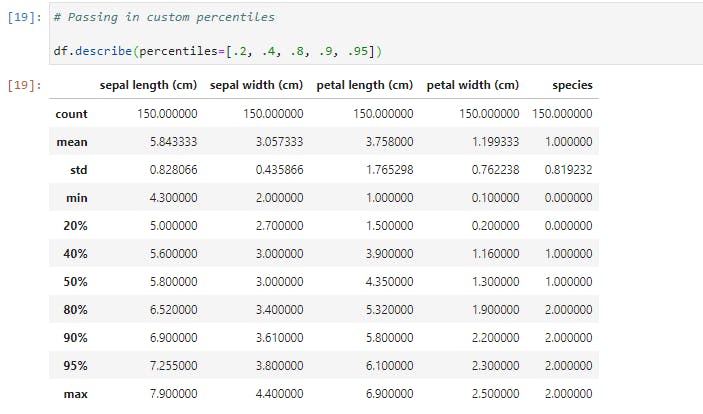
Now let’s check if there is any correlation between the features by calling .corr() method on the DataFrame;
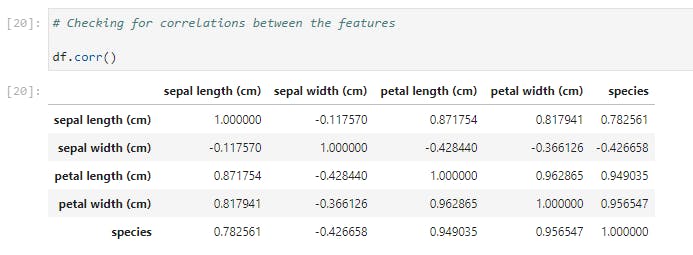
I find it surprising that sepal length and sepal width has the lowest correlation with a score of -0.117570.
Now that we’ve understood how to select subsets of our DataFrame and how to summarize its statistics, let’s try and visually inspect our data.
Data Visualization
You might wonder why we should even bother with visualization. The fact is that Data Visualization makes data easier for the human brain to understand and we can easily detect trends, patterns, and outliers in our data by performing a visual inspection.
So now that we understand the importance of visualization, let’s take a look at a pair of Python libraries that do this best.
The Matplotlib Library
Matplotlib is the great grandfather of all Python plotting libraries. It was originally created to emulate the plotting functionality of MATLAB, and it grew into a giant in its own right.

The first line imports Matplotlib while the 2nd line sets our plotting style to resemble R’s ggplot library.
Now let’s generate our first graph with the following code on our regular dataset;
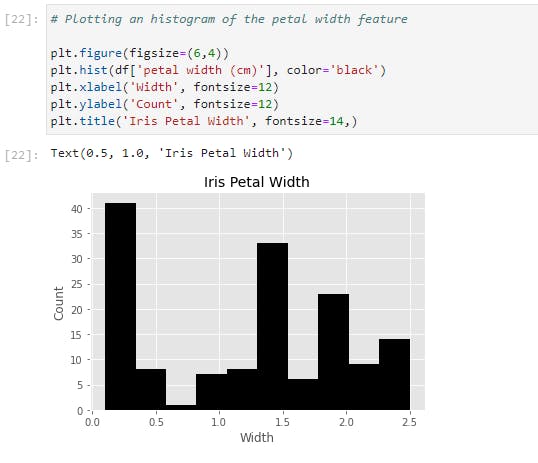
Let’s go through the code line by line:
- The first line creates a ‘plotting space’ with a width of 6 inches and a height of 4 inches.
- The second line creates a histogram of the petal width column and we also set the bar color to black.
- We labeled the x and y axes with ‘Width’ and ‘Count’ respectively while also setting the font size to 12.
- The final line creates the title “Iris Petal Width’ with a font size of 14.
All these together gives us a nicely labeled histogram of our petal width data!
Let’s now expand on that and generate histograms for each column of our Iris dataset;

Here’s the result of the preceding code;
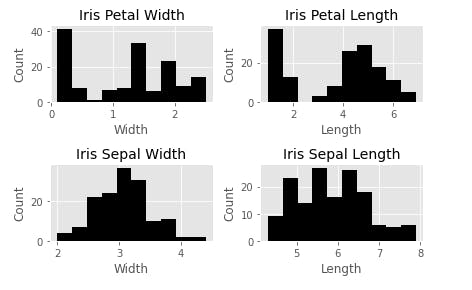
This is not the most efficient way to do this, obviously, but it is quite useful to demonstrate how Matplotlib works. With the previous example, this is almost self-explanatory except that we now have four subplots that can be accessed through the ax array. Another addition is the plt.tight_layout() call, which we nicely auto-space our subplots to avoid crowding.
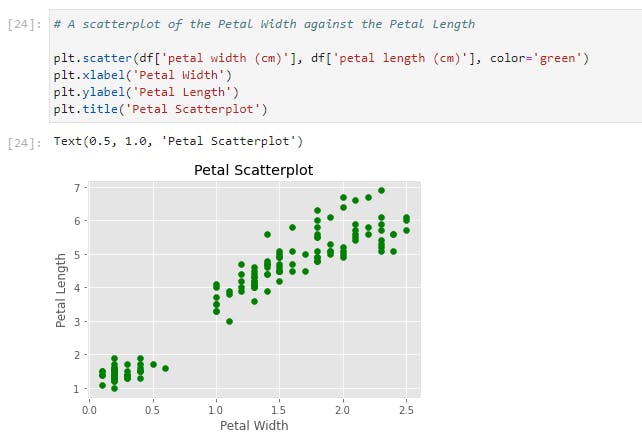
Let’s now take a look at the other kinds of plots available in Matplotlib. One is scatterplot. Here we plot the petal width against the petal length;
Another plot is a simple line plot. Here is a line plot of the petal length;
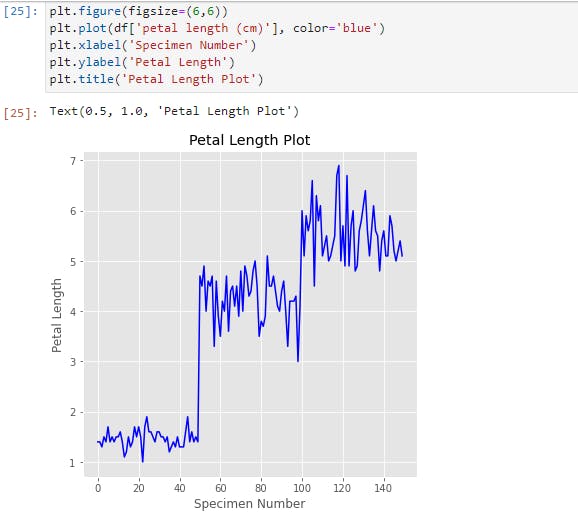
We can see here that there are three distinct clusters in this plot, presumably for each kind of species. This tells us that the petal length would most likely be a useful feature to denote the species if we build a classifier model.
Finally, let’s look at the bar chart. Here we’ll plot a bar chart for the mean of each feature for the three species of irises. Also, we will make it a stacked bar chart, to spice things up.
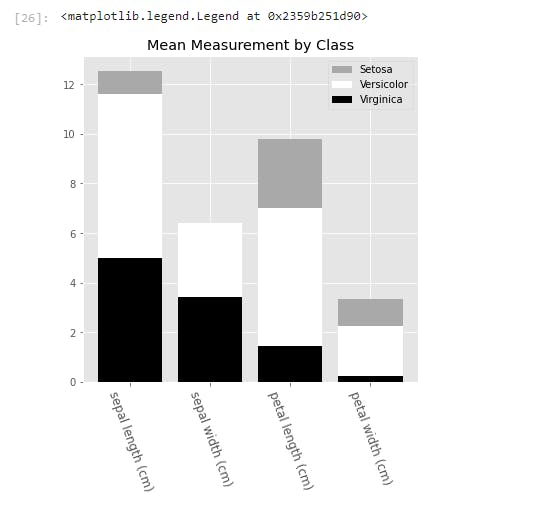
To generate the bar chart, we needed to pass in the x and y values into .bar(). Here, the x values is an array of the length of the features that we are interested in. We also called the .setxtickslabels() and passed in our preferred column names for display.
To line up the x labels properly, we also adjusted the spacing of the labels. This is why we set the xticks to x plus half the size of the bar_width.
The y values come from taking the mean of each feature for each species, and we called each by calling .bar().
We also pass in a bottom parameter for each series, to set the minimum y point and the maximum y point of the series below it. This is what creates the stacked bars.
And finally, we add a legend, which describes each series. The names are inserted into the legend list in order of the placement of the bars from top to bottom.
The Seaborn Library
The next visualization library we'll have a look at is Seaborn. Seaborn is built on Matplotlib, and it is built for statistical visualizations. This means that it is tailor-made for structured data (data in rows and columns).
Now let's have a taste of the power of Seaborn.

With just two lines of code, we'd get the following;
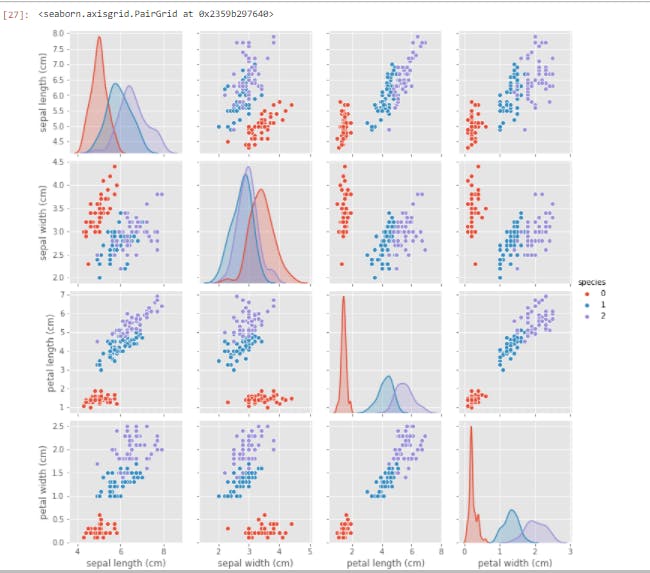
Having just gone through (what I hope it's not) a torrid time understanding the intricacies of Matplotlib, you'd appreciate the simplicity and ease with which we generated this plot. All of our features were created and properly labeled with just two lines of code.
You'd probably wonder why you'd want to use Matplotlib when Seaborn is so effortless to use. As I said earlier, Seaborn is built on Matplotlib, and you'd have to combine the functions of Seaborn with that of Matplotlib at times for modification. Let's try out this next visualization;

Here is the result of the preceding lines of code;
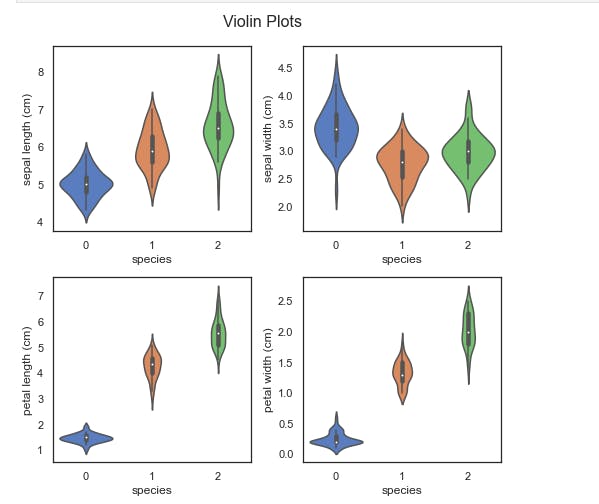
We have generated a violin plot for each of the four features. A violin plot displays the distribution of the features. For example, you can easily see that the petal length of setosa (0) is highly clustered between 1 cm and 2 cm, while virginica (2) is much more dispersed, from nearly 4 cm to over 7 cm.
You will also notice that we have used much of the same code we used when constructing the matplotlib graphs. The main difference is the addition of the sns.plot() calls, in lieu of the previous plt.plot() and ax.plot() calls.
There is a wide range of graphs that you can create with Seaborn and Matplotlib, and I'd highly recommend delving into the documentation for these two libraries.
The ones we've discussed here should go a long way in helping you visualize and understand your subsequent data.
Data Preparation
Having understood how to inspect and visualize our data, the next step is to learn how to process and manipulate our data. And here, we'd be working with map(), apply(), applymap(), and groupby() functions of Pandas. They are invaluable in working with Data, and they are very useful for feature engineering, which is the art of creating new features.
map
The map function works only on series, so we'll use it to transform a column of our DataFrame, which is a Pandas series. Suppose we decide that we're tired of using the species code numbers? We can use map with a Python dictionary to achieve this. The keys will be the code numbers while the values will be the replacements.
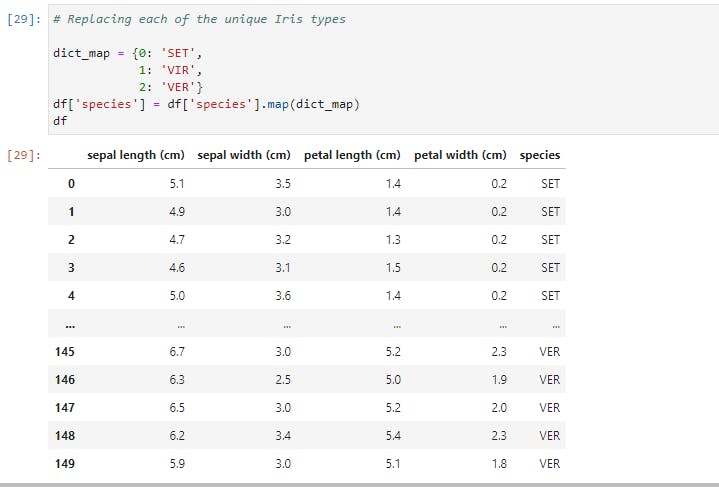
Here we have passed in our dictionary, and the map function ran through our entire data, changing the code numbers to their replacements everywhere it encounters them.
Had we chosen another name for our column, say better names, we'd have had a new column called better names appended to our DataFrame, and we'd still have the species column with the new better names column.
We could also pass a series or a function into our map function, but we can also do this using the apply function (as we'd see soon). What sets the map function apart is the ability to pass in a Dictionary, hence making map the go-to function for most single-column transformation.
apply
Unlike map, apply works on both series (single columns) and DataFrames (collections of series). Now let's create a new column based on Petal width using the Petal width's mean (1.3) as the deciding factor.
If the petal width is greater than the mean, we'd set wide petal to 1, while if it is lower than the mean, we'd set wide petal to 0.
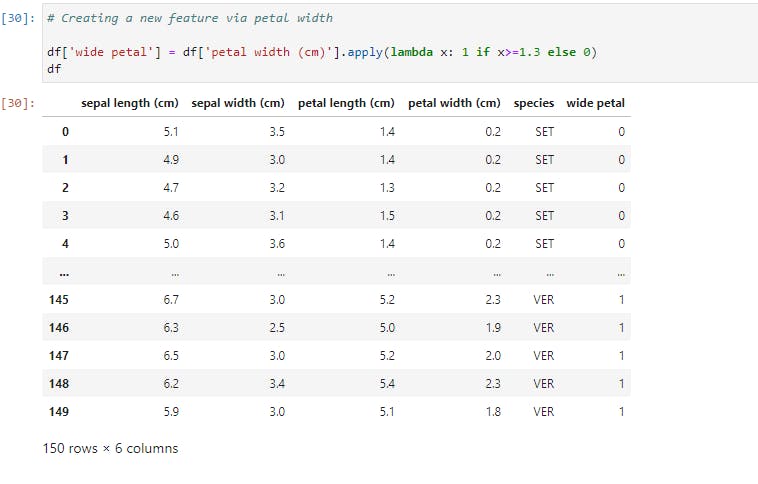
Here, we ran apply on the petal width column that returned the corresponding values in the wide petal column. The apply function works by running through each value of the petal width column. If the value is greater than or equal to 1.3, the function returns 1, otherwise, it returns 0.
This type of transformation is a fairly common Feature Engineering technique in Machine Learning, so it is good to be familiar with how to perform it.
Now, let's look at how to use apply across a DataFrame, and not just on a single Series. We'll create a new column based on the petal area.
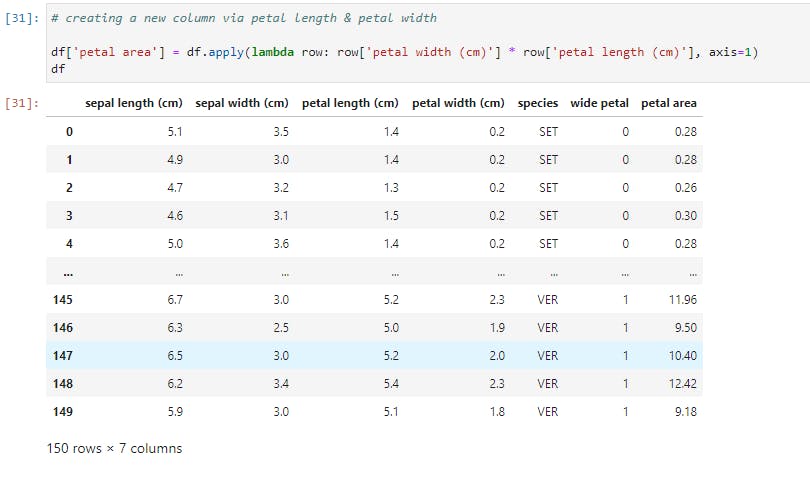
Notice that we called apply on the whole DataFrame here, and we also pass in a new argument, axis=1, so as to select the columns sequentially and apply the function row-wise. Had we set axis to 0, then the function would operate column-wise and throw up an error.
So for every row in the DataFrame, we multiply its petal width with its petal length, hereby creating a resultant series, wide petal.
This kind of power and flexibility is what makes Pandas an indispensable tool for Data Manipulation.
applymap
The applymap function is the tool to use when we want to manipulate all the data cells in a DataFrame. Let's take a look at this;
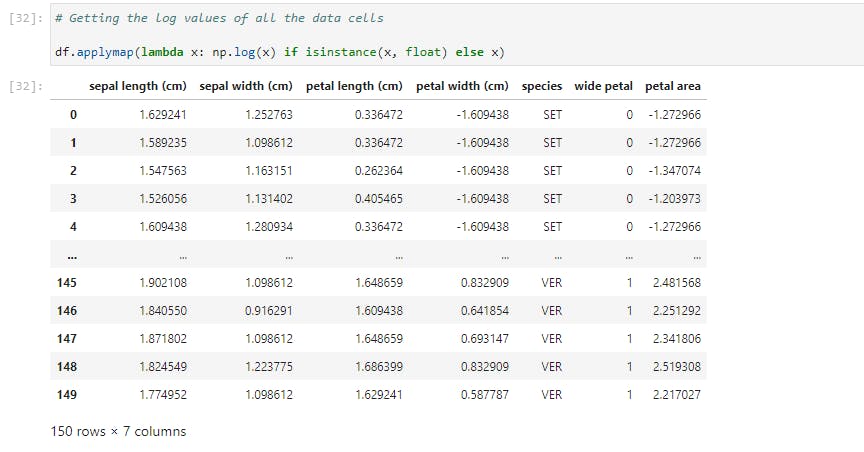
Here we performed a log transformation (using Numpy) on the entire data and the condition stated is that the data cell must belong to a float instance.
Common applications of applymap include transforming or formatting each cell based on meeting a number of conditions.
groupby
And now, let's have a look at an incredibly useful tool, but one that new Pandas users struggle to wrap their heads around. We'll examine a number of examples in order to illustrate its common functionalities.
The groupby function does exactly what it is named: it groups data based on a class or some classes you choose. Let's try out the first example;
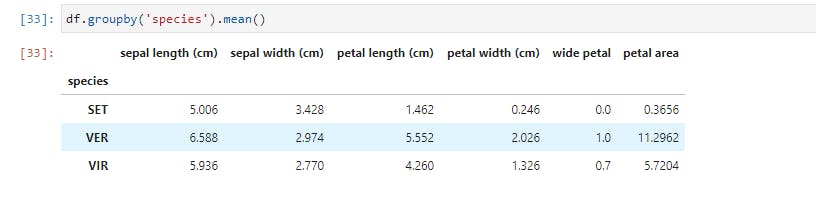
Here, data for each species is partitioned and the mean for each feature is provided. Now let's take a larger step and get descriptive statistics for each species;
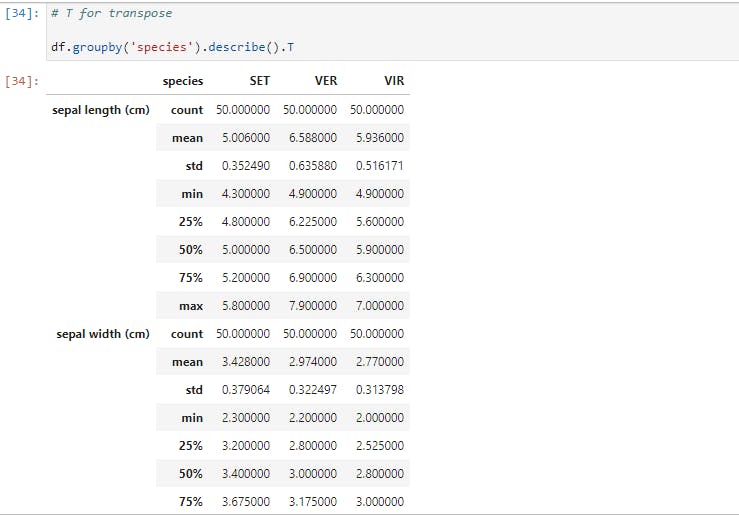
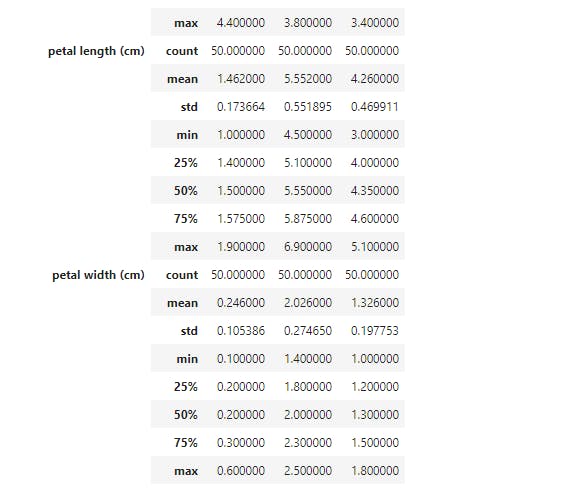
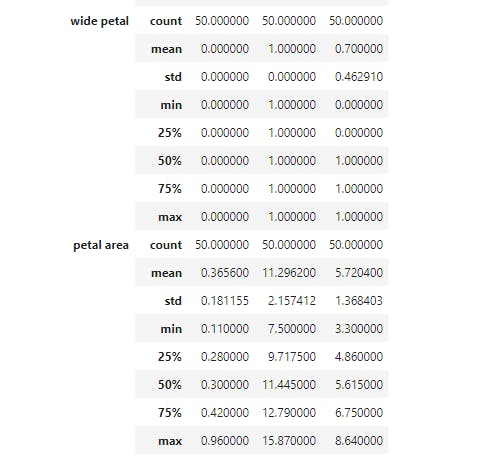
Now we have the total statistics breakdown. When visualizing, we noticed that there are some boundaries setting petal width and petal length of each species apart. So let's explore how we may use groupby to see that;
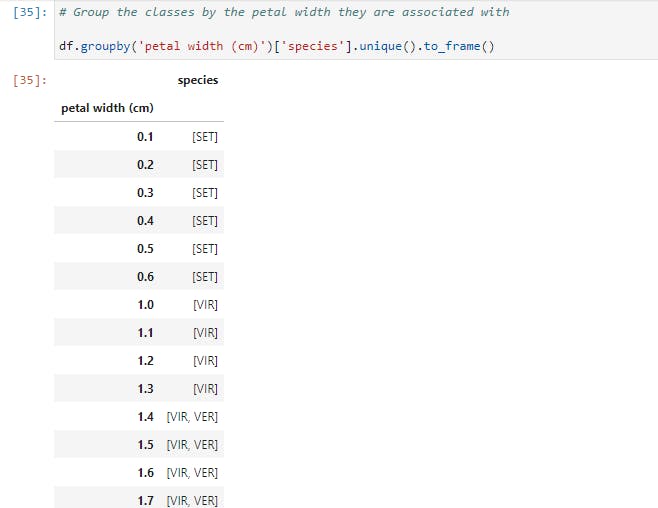
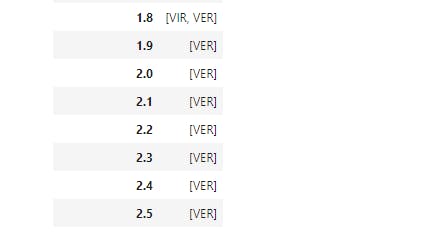
So here, we grouped the species by petal width, another step we could try (as an exercise) is to partition the data into brackets using apply.
Finally, let's have a look at a custom aggregation function.

Here, we grouped petal width by species and used a lambda function to get the difference between the maximum petal width and the minimum petal width.
Note that we've scratched at the surfaces of groupby and the other Pandas functions. I greatly encourage you to check out the documentation and learn more about the workings of Pandas.
Modelling and Evaluation
Now that you've had a solid understanding of how to manipulate and prepare data, we'll move on to the next step, which is Modelling.
Here, we'll discuss the primary Python libraries being used for Machine Learning.
Statsmodels
Statsmodels is a Python package built for exploring data, estimating models, and running statistical tests. Here, we will use it to build a simple Linear Regression model of the relationship between the sepal length and sepal width of the setosa species.
Let's create a scatterplot for visual inspection of the relationship;

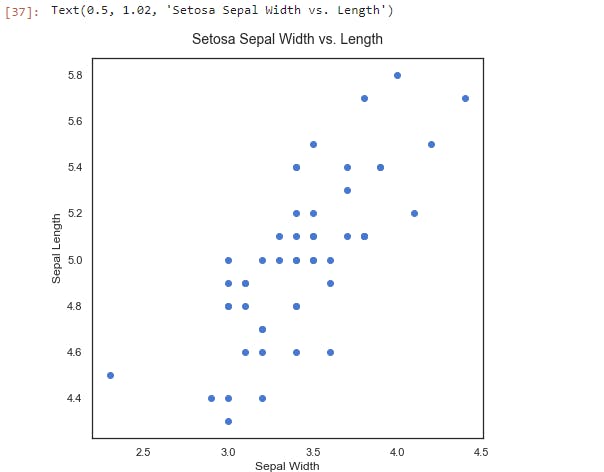
We can see that there's a positive linear relationship between the two features. The sepal width increases as the sepal length increases. The next step is to run a linear regression on the data using statsmodels to estimate the strength of the relationship.
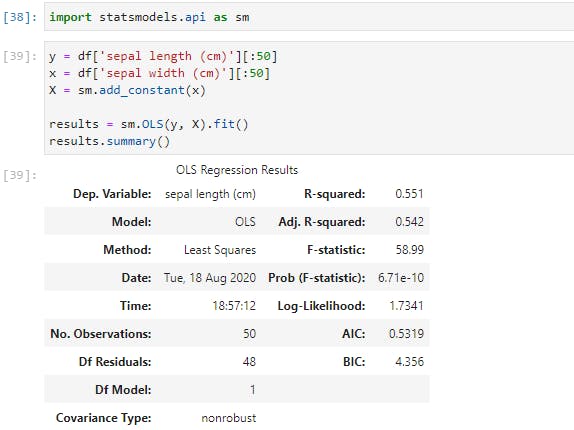
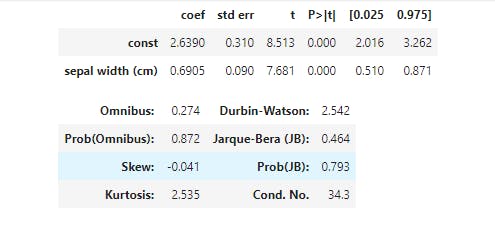
Now, here's the results of our simple regression model. Since this is a linear regression, the model takes the format of Y = Β0+ Β1X, where B0 is constant (or intercept) and B1 is the regression coefficient. Here, the formula would be Sepal Length = 2.6447 + 0.6909 * Sepal Width. We can also see that the R2 for the model is a respectable 0.558, and the p-value, (Prob), is quite significant.

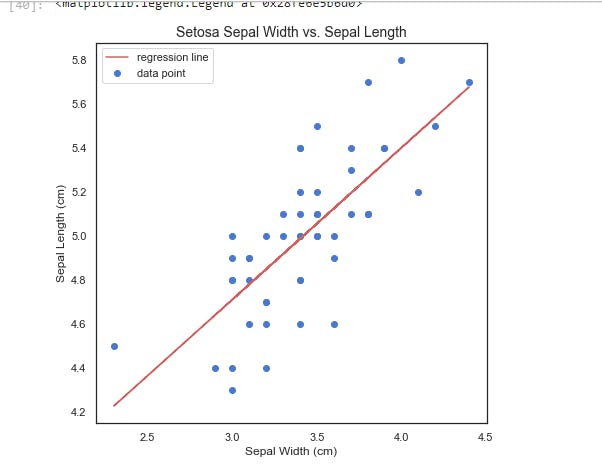
Plotting results.fittedvalues gets us the resulting regression line from our regression.
There are a number of other statistical functions and tests in the statsmodels package, but this by far, the most commonly-used test.
Let's now move on to the kingpin of Python machine learning packages; All Hail Scikit-learn!
Scikit-Learn
Scikit-learn is an amazing Python library with outstanding documentation, designed to provide a consistent API to dozens of algorithms. It is built upon and is itself, a core component of the Python scientific stack, which includes NumPy, SciPy, Pandas, and Matplotlib. Here are some of the areas scikit-learn covers: classification, regression, clustering, dimensionality reduction, model selection, and preprocessing.
Now, let's build a classifier with our iris data, and then we'll look at how we can evaluate our model using the tools of scikit-learn:
- The data should be split into the predictors and the target; The predictors (independent variables) should be a numeric
n × mmatrix, X, and the target (dependent variable), y, ann × 1vector. - These are then passed into the
.fit()method on the chosen classifier. - And then we can use
.predict()method to make predictions on new data.
This is the greatest benefit of using scikit-learn: each classifier utilizes the same methods to the extent possible. This makes swapping them in and out a breeze. We'll see this in action soon.
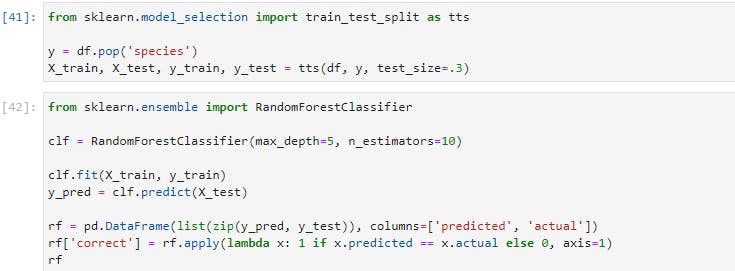
Now let's run this line of code;

In the preceding lines of code, we've built, trained, and tested a classifier with 95% accuracy level on our iris dataset. Now let's go through each step one by one;
- We imported
train_test_splitfrom scikit-learn, which is shortened tosklearnin import statement.train_test_splitis a module for splitting data into training and testing sets. This is a very important practice in building models. We'd train our model with the training set and validate our model's performance with the testing set. - In the 2nd line, we separated the target variable, which is
species, from the predictors. (In mathematical lingua, we created our X matrix and our y vector) - Then we used
train_test_splitto split the data. As you'd notice, we settest_sizeto 0.3, which means that the testing set should be 30% of the whole data. Thetrain_test_splitmodule also shuffles our data, as the order may contain bias which we won't want the model to learn. - Moving to the next cell, we imported a Random Forest Classifier from the
sklearnmodule. we instantiated our forest classifier in the next line using 10 Decision Trees, and each tree has a maximum split depth of five, in a bid to avoid overfitting. - Next, our model is fitted using the training data. Having trained our classifier, we called the predict method on our classifier passing in our test data. Remember that the test data is the data that the classifier has not seen yet.
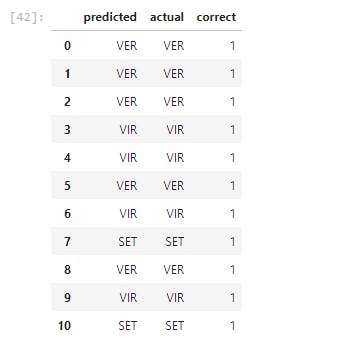
- We then created a DataFrame of the actual labels vs the predicted labels. Afterward, we totaled the correct predictions and divide them by the total number of instances, which then gave us a very high accuracy.
Let's now see the features that gave us the highest predictive power;

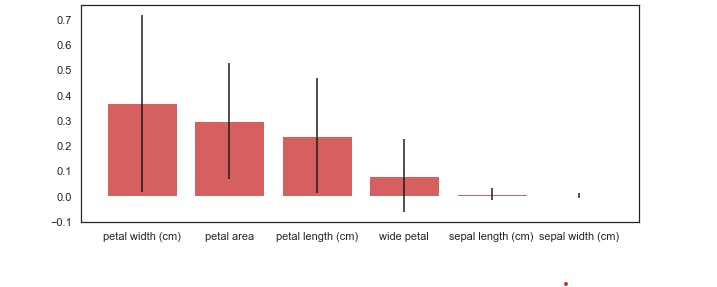
As we expected, based upon our earlier visual analysis, the petal length and width have more discriminative power when differentiating between the iris classes.
And as I mentioned when we checked the correlation between our features, sepal length and sepal width seem to contribute very little to our model's accuracy.
How did we get this? The random forest has a method called .feature_importances_ that returns the relative performance of the feature for splitting at the leaves. If a feature is able to consistently and cleanly split a group into distinct classes, it will have high feature importance.
You'd notice that we included the standard deviation, which helps to illustrate how consistent each feature is. This is generated by taking the feature importance, for each of the features, for each of the ten trees, and calculating the standard deviation.
Let's now take a look at one more example using Scikit-learn. We will now switch out our classifier and use a support vector machine (SVM):

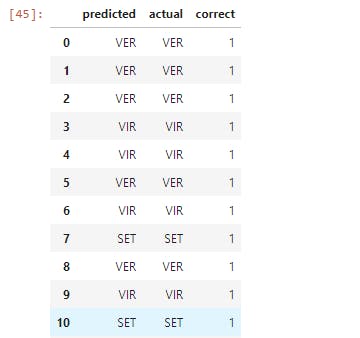
Now let's execute the following line of code;

Here we used SVM instead of Random Forest Classifier without changing any of our code, except for the part where we imported in Support Vector Classifier and instantiated the model. This is just a taste of the unparalleled power that Scikit-learn offers.
I'd strongly suggest that you'd go to the Scikit-learn docs and check out some of the other ML algorithms that Scikit-learn has to offer.
Final Notes
With this, we're done with this introductory guide to Data Analysis and Machine Learning.
In this article, we learned how to take our data, step by step, through each stage of Data Analysis and Machine Learning. We also learned the key features of each of the primary libraries in the Python scientific stack.
Here is the link to the code and explanations on GitHub.
In subsequent articles, we will take this knowledge and begin to apply them to create unique and useful machine learning applications. Stay tuned!
Meanwhile, like and share this article if you find it insightful. You may also say hi to me on Twitter and LinkedIn. Have fun!
Note: This article was heavily inspired by Python Machine Learning Blueprints by Alexander T. Combs.