The Data Science/Machine Learning Workflow


A definitive guide for building end-to-end data-driven applications
Machine Learning is rapidly changing our world. Being the focal point of artificial intelligence, it is rare to spend a day without reading about how machine learning is transforming the way we live positively (and negatively by procreating job-stealing robots and terminators).
Applications of machine learning are mostly subtle (some are quite loud) but progressive improvements in how we interact with computers and the world around us and Machine Learning has become a fixture of our daily lives.
With the hype on Data science in recent years, there’s probably not a better time than now to dive into building Machine Learning applications and of course, understand the proper way to go about building those applications.
What to note before building data-driven applications
Even though being a data scientist is a sexy profession, there is a huge gap between the teaching material and reality. Data science is not about statistics and increasing your model accuracy by 0.00001 percent. It is all about solving real problems and fulfilling human needs. Also, when solving real problems, there’s an important factor to note;
> Building machine learning applications first and talking to the customers later makes the process flawed, hence the products will most likely miss targets.
Machine learning products should be created with the end-users in mind at all times! Understanding the problem scope while also investing time and thought on the final goal and user experience should always be the precedent to the actual implementation.

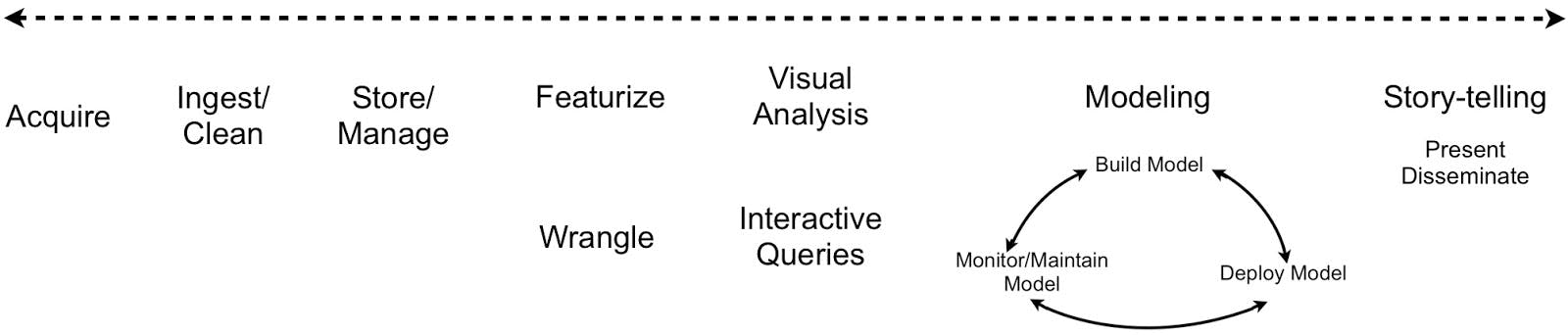
The Process
Building machine learning applications is quite similar in approach to the software engineering process, but there’s a key difference; the need to work with data.
The success of the project is mostly dependent on the quality of the acquired data, as well as how well the data is handled. And because working with data falls into the domains of Data Science, it is necessary to understand the data science workflow.
The steps involved are the order below;
- Acquisition
- Inspection
- Preparation
- Modeling
- Evaluation
- Deployment
In most cases, you’d frequently have to cycle between some of the steps until the optimal solution has been achieved. For example, one would probably shuttle between inspecting and preparing the data couple of times before having the data ready for Modelling. There’d most likely be a number of to-and-fro movement when modeling and evaluating, to obtain the best-performing model.
Having said that, let’s discuss each step in detail;
Acquisition
Data for machine learning applications might come from diverse sources. It might come in CSV files, one might have to query databases, pull down server logs, maybe even require building a custom scraper.
Data also exists in different formats. Data scientists usually work with text-based data but there has been an upward spike in the usage of images, audio, and video-based data in recent years.
Nevertheless, while acquiring the data is the first step, it is equally important to understand what information is present in the data, and which information is not in the data.
Inspection
Inspecting the data is the next step after data acquisition. It is very important to examine the data, and this is done by checking things that are either impossible or highly unlikely. For example, you might check if there’s only one unique identifier, if the price is positive in all cases, or if the facts in the data contradict one another. And also, always check the outliers. Do make sense?
And finally, running statistical tests on the data and visualizing the data is a very good tradition. Remember that the outcome of your models is only as good as the data you build the model with.
> If the foundations are destroyed, what can the righteous do?
Preparation
Once the data is ready, the next step is to prepare the data and configure it into a format that is suitable for modeling. This stage includes lots of processes, this is where imputing, filtering, aggregating, and transforming take place. The processes you would carry out are highly dependent on the type of data, as well as the machine learning algorithms that you’d be utilizing. For example, you don’t have to impute your categorical data if you are making use of an algorithm like CatBoost, likewise, the transformations to be carried out on natural language-based text would be different from the ones required by time-series data.
Modeling
Modeling is the next phase after data preparation. It is all about selecting an appropriate algorithm and training the model with the data.
One of the basic steps involved is to split the data into training, validation, and testing sets. This might seem illogical, as the general conception is that “more data produces better models”. But splitting our data allows us to get quality feedback on how our model is performing and also to avoid the mortal sin of modeling; overfitting.
Evaluation
Now that we have a nice model, the key question to ask is how good is the model is? Evaluation is the process that brings the answer to this question.
There are numerous ways to measure the performance of our model but the ways are also heavily dependent on the type of ML algorithm being used and the kind of data one is working with.
There are lots of technical and confusing terms like F1-score, mean squared error, and Euclidean distance, but in the end, all they do is to measure the distance between the actual prediction and the estimated prediction.
Deployment
Once one is satisfied with the model’s performance, deployment is next. This can take different forms depending on the use case. Some of the common situations are listed below;
- Utilization as a feature within a larger application
- A custom-tailored web (or mobile) application
- A cron job (a task or script scheduled to run automatically at intervals)
- No deployment, but insights are documented as findings in a report or as a presentation.
Summary
In this article, we outline the right way to build a data-driven project which is by understanding the problem domain and understanding what the end-users want. We also outline the steps involved in building machine learning applications.
Subsequent articles would cover the practical aspects of all the steps outlined in this article.
If you find this read insightful, give some claps, utilize it, and share it with others. And also, you can say to me on Twitter and LinkedIn. Bye!